Sysconf
Einleitung / Motivation
Die System-Konfiguration eines Unix-Systems besteht nahezu vollständig
aus Textdateien, die normalerweise "per Hand", also mit einem
Text-Editor wie "vi" direkt bearbeitet werden oder mit einem
grafischen Konfigurationswerkzeug.
Ganz unabhängig davon, ob es sich nun um eine Text- oder Binär-Datei
handelt, und unabhängig davon, wie sie erstellt und/oder gepflegt
wird: Diese Arbeiten finden immer direkt auf dem betroffenen
Unix-Rechner statt.
Bei einer großen Anzahl (meines Erachtens schon ab 2 bis 3) an
Unix-Rechnern ist dieses Vorgehen nicht nur sehr mühsam und
zeitintensiv, sondern auch noch fehlerträchtig,
da eine Änderung in einer Datei mehrfach, in großen Umgebungen auch
hunderte bis tausende Mal durchgeführt werden muß.
Da liegt es also nahe, die Konfigurationsdateien auf einem zentralen
Server zu lagern und nur dort zu ändern.
Allerdings stellt es sich sehr schnell heraus, daß viele
Konfigurationsdateien nicht auf allen Rechnern identisch sind,
sondern sich teilweise nur marginal unterscheiden. Folglich müsste
man für jeden Rechner einen Satz Konfigurationsdateien auf dem
zentralen Server bereithalten. Das alleine wäre noch kein
allzugroßes Problem, aber was ist bei einer Änderung? Wieder
hunderte von Dateien ändern? Das wäre jetzt zwar schon zentral
möglich, aber das ist immer noch sehr zeitaufwändig und
fehlerträchtig.
Sinnvoll wäre es also, nur eine Standard-Datei und deren
Spezial-Einträge für die einzelnen Rechner zu speichern. Damit wären
wir also bei einem Konfigurations-Management-Tool...
Ein weiterer Grund für den Einsatz eines
Konfigurations-Management-Tools ist die Standardisierung der
betroffenen Unix-Rechner.
Das heißt, sie werden so konfiguriert, daß sie in möglichst vielen
Aspekten gleich sind.
Die Variationen, dort wo Rechner verschieden sind, sollen möglichst
gering, durch einfache Regeln erkennbar und zentral gespeichert
sein.
Dies ist die Grundvoraussetzung um Abläufe, die mehrere Rechner
betreffen, automatisieren zu können (Systemmanagement, Jobsteuerung,
etc.) und die Betriebskosten so gering wie möglich zu halten.
Ohne eine Tool-Unterstützung kann man zwar eine Hand voll
Unix-Server standardisieren, aber ab einer gewissen Anzahl an
Administratoren und Server funktioniert das manuell nicht mehr.
Welche Anforderungen muß ein Konfigurations-Management-Tool erfüllen?
-
Abdeckung möglichst vieler Unix-Derivate des Marktes, zum Beispiel: Linux, AIX, Solaris
-
Abdeckung möglichst vieler Unix-ähnlicher Plattformen,
z.B. Firewalls, Hardware-Management-Konsolen,
Virtualisierungs-Konsolen (z.B. ESX)
-
einfacher Aufbau der Konfigurationsdatenbank
-
die Konfigurationsdatenbank sollte einfaches Hinzufügen, Suchen, Ersetzen und Löschen ermöglichen
-
Unterstützung von Auswertungen nach Betriebssystemen, Rechnern, Parametern, etc.
-
Ermöglichen von Zusammenfassungen von Konfiguration, um Doppelarbeit für unterschiedliche Derivate zu vermeiden
-
flexible Einsatzmöglichkeiten, um möglichst viele Parametrisierungen leicht zu handhaben
-
die Möglichkeit bieten alle Ziel-Systeme auf dem aktuellen Stand zu halten
-
Spezial-Konfigurationen einzelner Rechner sollten ebenso effizient zu handhaben sein, wie Standard-Konfigurationen
-
Unterstützung variabler Rechner-Zugänge: ohne Agent (SSH) oder mit Agent
-
Unterstützung von erhöhten Sicherheits-Anforderungen: Zugang zu den Ziel-Rechnern per Benutzer plus Sudo oder Root.
-
Protokollierung aller Änderungen: Wer hat wann was geändert?
-
Erstellung einer Konfigurations-Übersicht der einzelnen Rechner
-
Ermöglichen von Teil-Standardisierungen für Einzel-Rechner, also z.B. nur 10 Konfigurations-Dateien statt alle.
Lösung: Sysconf
Das Tool Sysconf ist im Rahmen meiner
Diplomarbeit
entstanden.
Mit Sysconf können einer oder mehrere Rechner anhand einer
Datenbank konfiguriert werden. Es kann dabei alles, was unter
Unix in einer Datei gespeichert wird in die Datenbank
aufgenommen werden. Beispielsweise kann die Datei
/etc/sendmail.cf mittels Sysconf an einzelne Rechner
angepaßt und auf diese Rechner übertragen werden.
Optional kann auch der
sysconf-client benutzt
werden. Dazu sind aber noch diese beiden Module notwendig:
RemoteClient.pm und
RemoteServer.pm.
Oder noch besser der Sysconf-Client mit SSL-Verschlüsselung:
sysconf-client-ssl.
Dazu sind noch diese beiden Module notwendig:
RemoteClientSSL.pm und
RemoteServerSSL.pm.
Details sind in der
Manpage zu Sysconf zu
finden.
Download: Sysconf
Ablauf (Überblick)
Das Konfigurations-Management bzw. die Standardisierung kann mit
Sysconf wie folgt erledigt werden:
Phase 1: Erstellen bzw. Pflegen der Konfigurationsdatenbank:
Die Konfigurationsdatenbank besteht aus Dateien und Skripten, die
die Einstellungen darstellen.
Die Unix-(Ziel-)Rechner werden von einem zentralen Rechner, auf dem
Sysconf läuft, betankt. Dort liegt auch die
Konfigurations-Datenbank.
Die Konfigurationsdateien aller Zielrechner werden nicht mehr auf
dem Zielrechner selbst geändert, sondern nur in der
Konfigurations-Datenbank.
Phase 2: Manueller bzw. automatischer Rechnerabgleich
(Verteilung/Lauf):
Der Systemverwalter gibt Art und Umfang des Abgleichs
vor. (Manueller Abgleich)
Beim automatischen Abgleich wird der Zielrechner mit der kompletten
Konfiguration betankt.
Der Abgleich der Zielrechner kann wahlweise über ssh oder
sysconf-client erfolgen.
Der Zugang zum Sysconf-Client-Rechner kann über Root oder einen
anderen Benutzer mit ensprechenden sudo-Rechten erfolgen.
detaillierter Überblick
Welche Daten verwaltet Sysconf?
In Sysconf sind folgende Daten gespeichert:
Eine Liste aller Rechner, die mit Sysconf verwaltet werden
(hosts.sc). In dieser Liste stehen folgende Informationen:
-
Rechnername (z.B. neptun)
-
Betriebssystem (z.B. Fedora-7)
-
Liste von sog. Subsystemen und Klassen.
In einem Subsystem sind eine oder mehrere Konfigurationsdateien
enthalten. Mehrere Subsysteme können auch zu einer Klasse
zusammengefasst werden.
-
Optional ein zu verwendendes Interface über das der Rechner erreicht
werden kann/soll (in der Regel gibt man hier ein Interface in einem
Administrations-LAN an).
Für jeden Rechner gibt es eine Variablen-Datei (z.B. neptun.var) in
der alle für diesen Rechner relevanten Spezialitäten enthalten
sind.
Für jedes Betriebssystem gibt es eine Sammlung an
Konfigurationsdateien. Hier kann man wieder zwischen diesen
Datei-Typen unterscheiden:
-
Unveränderliche Dateien: Diese werden direkt auf den Ziel-Rechner
übertragen.
-
Templates: Diese Dateien sind nur "Gerüste", die erst mit den
Inhalten der Variablen aus der Variablen-Datei gefüllt werden und
dann auf den Ziel-Rechner übertragen werden.
-
Links. Damit können Unix-Links verwaltet werden.
-
Dateien, die gar keine sind: Shell-Kommandos.
Diese werden bei der Sysconf-Verteilung genauso behandelt wie
Dateien, mit dem einzigen Unterschied, daß sie nicht kopiert
werden, sondern ausgeführt werden.
Diese Daten sind in einer Verzeichnisstruktur als Flat-Files
abgelegt.
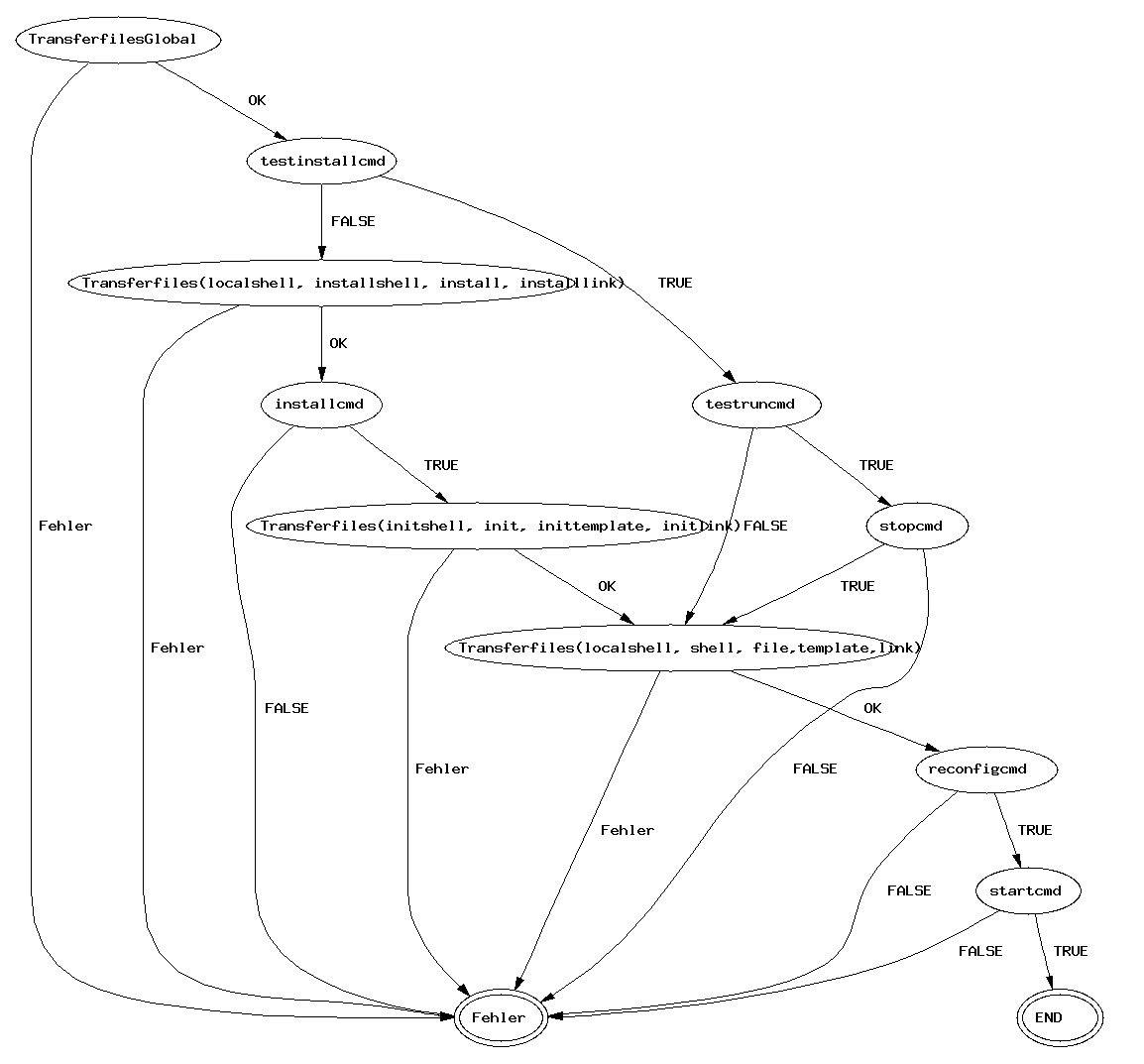
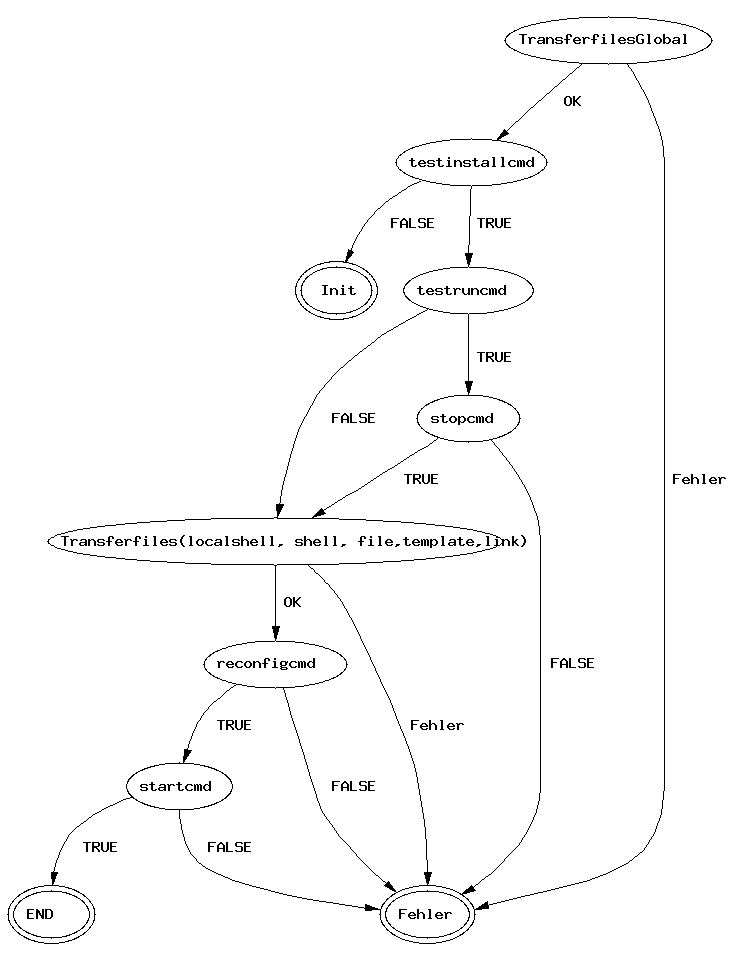
Für jedes Betriebssystem und jedes Subsystem gibt noch noch Start-,
Stopp-, und Reconfigure-Kommandos. Das sind in der Regel
selbstgeschriebene Shell-Skripte, die ein "Subsystem"
z.B. durchstarten. So ist es beipsielsweise notwendig einem
Daemon-Prozess nicht nur eine neue Konfigurations-Datei zu geben,
sondern ihn auch neu zu starten, sodaß er die neue Datei einlesen
kann.
Die Reihenfolge der Ausführung dieser Kommandos ist in folgenden
Ablaufplänen illustriert:
Vorteile und Möglichkeiten:
-
Es wird keine Information doppelt vorgehalten.
-
Durch Links können Betriebssystem-Versionen auf Basis-Versionen und
Spezialfälle reduziert werden. Beispiel: Es gibt ca. 500
Konfigurationsdateien für Suse 6.1, 6.2, 6.3 und 6.4. Davon sind
für die einzelnen Versionen 450 identisch. Normalerweise müsste
man dazu also 2000 Dateien pflegen. Das heißt
also, daß man dank der Links nicht 2000 Dateien im
Sysconf-Repository pflegen muß, sondern nur 450 zzgl. der
Spezial-Versionen, also nur 650 (=450+50*4).
Eine noch stärkere Reduktion ergibt sich, wenn man mehrere Unices in
Sysconf aufnimmt: Die Ähnlichkeiten von AIX, Solaris und Linux sind
ziemlich groß.
-
Durch eine einzige Änderung im Repository in einer Datei kann diese
auf allen Rechnern, die diese Datei erhalten, diese verändert
werden.
Wie verteilt Sysconf die Konfigurationsdateien?
Sysconf kann über eine oder mehrere der folgenden Methoden mit dem
Ziel-Rechner kommunizieren:
-
SecureShell: ssh/scp
-
Sysconf-Client (eine direkte TCP/IP-Socket-Kommunikation zwischen
Sysconf-Master und einem Sysconf-Client-Daemon.)
-
Sysconf-Client-SSL (eine direkte SSL-TCP/IP-Socket-Kommunikation
zwischen Sysconf-Master und einem Sysconf-Client-Daemon.)
-
RemoteShell: rsh/rcp (Das dient aber nur als "Fall-Back", wenn
die ersten beiden Möglichkeiten nicht genutzt werden können.
Dabei kann Sysconf sowohl auf Master-, als auch auf Client-Seite als
Root oder als User laufen. Wenn Sysconf als User läuft, dann ist auf
Client-Seite noch eine passende Sudo-Konfiguration nötig, um dem
Sysconf-Client die passenden Rechte zu geben.
Und nun viel Spaß beim Konfigurieren und Standardisieren!
{kind=link}
{kind=link}
